환급미션 23일째..
컴퓨터 구조 - 메모리 구조 - 컴퓨터 성능 개선을 위한 메모리 관리 -1
컴퓨터 구조 - 메모리 구조 - 컴퓨터 성능 개선을 위한 메모리 관리 -2
- Cache memory의 다양한 mapping 기법 ( associative mapping / direct mapping / set-associative mapping )
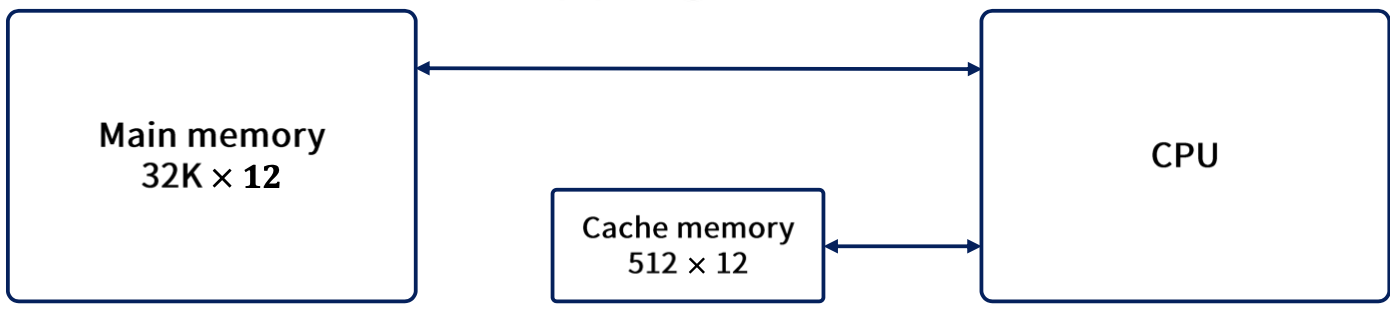
이와 같은 상황으로 가정한다.
main memory : 12bit 32K 워드를 저장
cache memory : 512 words / 주어진 시간 내 저장
cpu - main/cache 모두 통신 가능
15bit의 주소를 cache로 보내어 hit가 발생하면 캐시로부터 12bit의 데이터를 받아들인다.
miss가 발생하면 main memory로부터 워드를 읽고, 이를 cache로 이동하여 저장한다.
* Associative mapping

가장 빠르고, 융통성 있는 캐시 구조
인자 레지스터(argument register)에 cpu의 15비트 주소 (8진수 1자리는 2진수 3자리에 해당, 3x5자리 = 15bit) 가 놓여지고,
associative memory 내 주소와 같은 12bit 데이터 (마찬가지로, 3x4자리=12bit) 를 읽어 cpu로 보낸다.
miss인 경우 main memory에서 해당 자료를 찾아 캐시로 옮긴다.
•캐시에 여유공간이 있을 경우 - 그 공간에 주소, 데이터를 저장
•캐시에 여유공간이 없을 경우 - 기존 캐시 주소와 데이터 쌍 중 주어진 알고리즘에 의해 해당 주소 데이터쌍으로 대체된다.
( 이러한 알고리즘 구현 때문에 캐시 구축에 어려움이 발생함 )
* Direct mapping

위에서 보는 것과 같이 cpu 주소를 쪼개서 tag field + index field로 나눈다.
tag field : cache에서 동일한 인덱스로 충돌이 발생할 경우 활용
index field : cache의 인덱스로 활용
동일한 인덱스, 다른 태그를 보유한 워드가 반복해서 접근할 때, hit rate가 떨어질 가능성이 높다.
direct mapping 의 예시는 아래와 같다.
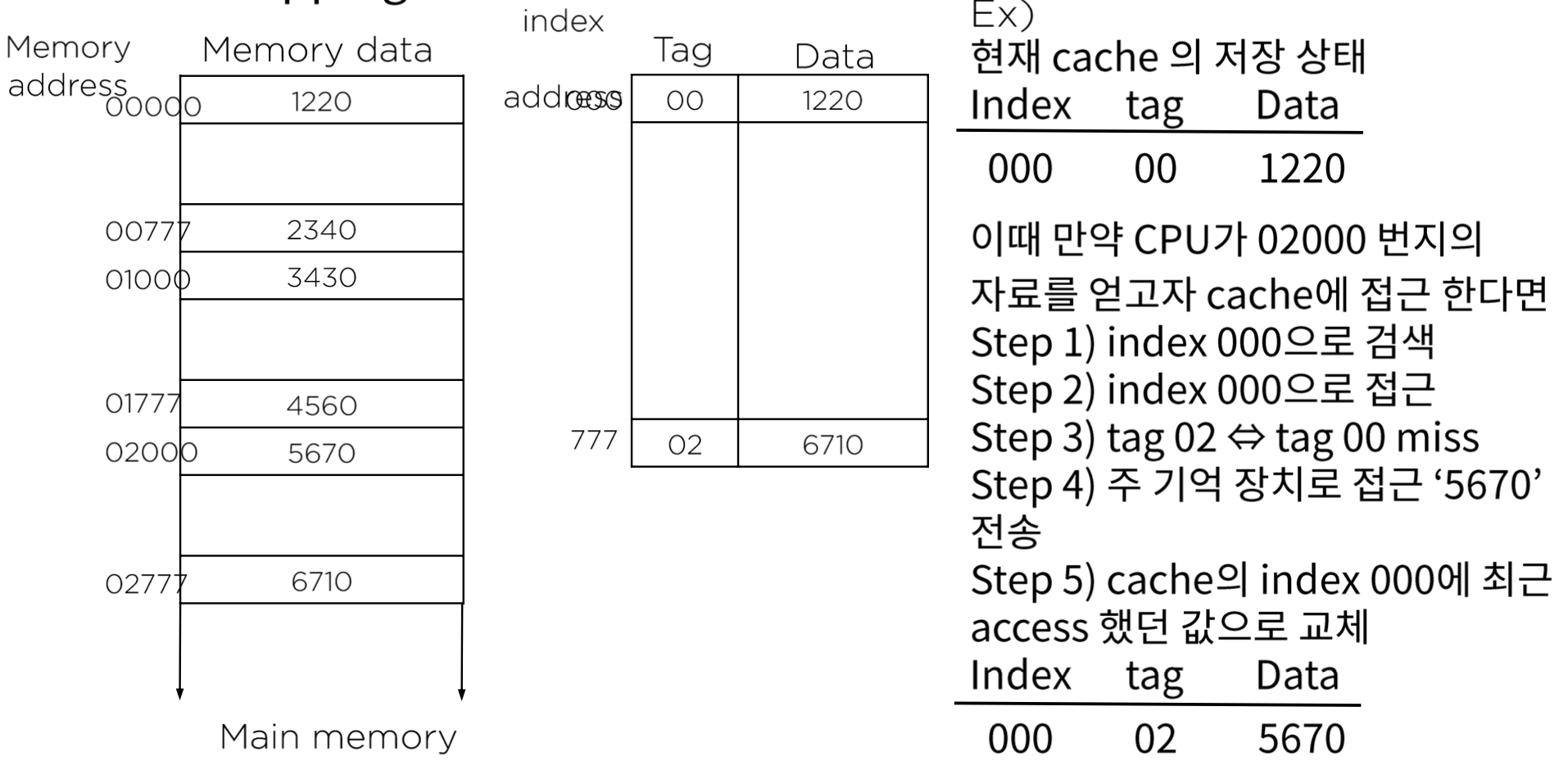
cpu가 02000 번지의 자료를 얻고자 할 때
인덱스 000으로 검색, 접근하였을 때
태그값이 예시와 같이 00일 경우 miss가 발생하게 되고,
main memory로 접근하여 02000의 '5670'을 읽어온 후
접근했던 캐시의 인덱스 000에 접근하여 읽어온 값을 저장한다.
* Set- associative mapping ( 조금 더 개선된 방식 )
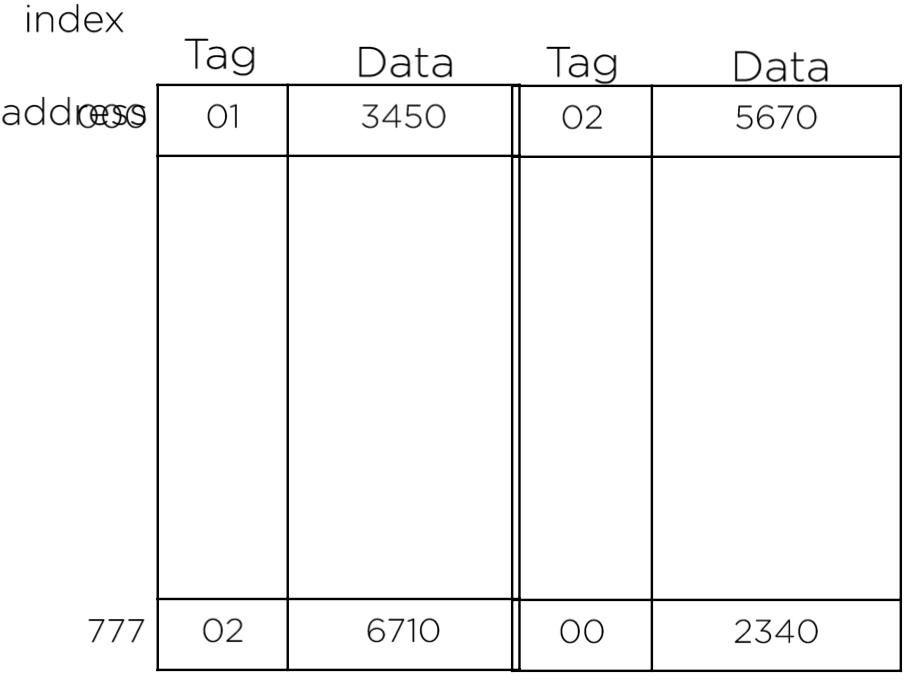
캐시의 각 워드는 같은 인덱스 주소 아래에 두 개 이상의 메모리 워드를 저장하여 direct mapping의 단점을 보완한다.
큰 규모의 cache는 히트율을 개선할 수 있으나,
비교 논리회로가 복잡해지고, 기존 데이터의 대체 알고리즘 또한 복잡해진다.
- 가상메모리

- 메모리 관리 하드웨어


컴퓨터 구조 - 메모리 구조 - 다양한 기억장치들에 대한 이해 -1
컴퓨터 구조 - 메모리 구조 - 다양한 기억장치들에 대한 이해 -2
- 주 기억 장치 - DDR
* SDRAM ( synchronous dynamic ram )
: DRAM의 발전된 형태, 동기식 DRAM (제어장치 입력 = 클럭펄스 주기)
* SDR ( single data rate )
: SDRAM -> 클럭 펄스의 변이 시(0<->1) 한 차례의 정보전송을 허용하는 구조
* DDR SDRAM ( double data rate SDRAM )
: 클럭 신호의 상승 및 하강 ( 0->1->0 ) 구간에서 데이터를 전송 (double pumping)
클럭 주파수를 증가시키지 않고 기존 방식에서 두 배로 전송속도가 향상된다.
* DDR2 SDRAM
: 향상된 버스 신호에 의해 DDR2의 free batch buffer는 4비트가 된다.
내부 클럭 속도는 DDR과 동일,
향상된 I/O 버스 신호에 의해 전송 속도가 증가한다.
* DDR3 SDRAM
: DDR2 모듈에 비해 40% 전력 소비
ASR(automatic self-refresh), SRT(self-refresh temperature) 등의 기능 추가
* DDR4 SDRAM
: 낮은 작동전압 (1.2V), 높은 전송속도
DBI(data bus inversion), CRC(cyclic redundancy check), CA parity 등의 기능 추가
신호 무결성 향상, 데이터 전송/액세스 안정성 향상
- 보조 기억장치
* SSD ( solid state drive )
빠른 데이터 입/출력 속도
HDD는 자기 디스크, SSD는 플래시 메모리로 구성 ( 신호->상태값 저장할 수 있는 회로를 보유 )
모터가 없어져서 소음 감소 및 소모전력/발열 감소
* RAID ( redundant array of inexpensive (or independent) disks )
이렇게 직관적인 작명은 처음 본다...
저렴한 여러 개의 하드디스크를 묶어 하나의 기억장치로 사용하게 하는 방식의 장치
데이터를 나누는 방법이 다양한데,
이런 방법들을 레벨이라 하고, 레벨에 따라 신뢰성이 높아지거나 성능이 향상되는 등의 다양한 목적을 갖는다.
흔히 쓰이는 레이드 레벨은 0~6이 있다.
RAID level 0 : parity ( 오류 검출기능 )이 없다. 개선된 성능에 추가적인 기억장치를 제공한다는 장점이 있지만 실패할 경우 자료의 안전을 보장할 수 없다.
RAID level 1 : parity는 없지만 단순 복사본으로 구성되며 디스크 오류/단일 디스크 실패에 대한 실패 방지 기능이 있다.
RAID level 3,4 : parity가 단순 제공되며 3은 적어도 3개의 디스크, 4는 2개의 디스크로 구성된다.
RAID level 5 : parity가 배분되며 적어도 3개의 디스크를 갖는다.
이렇게 여러 가지 레이드 레벨이 흔히 쓰이고 있다.
소프트웨어 베이직 - c언어의 기초 - 15. 함수 포인터
c언어에서 함수의 이름을 이용해 특정한 함수를 호출한다.
함수 이름은 메모리 주소를 반환
반환 자료형 (*함수명)(매개변수) = 함수명;
-> 특정한 함수의 반환 자료형을 지정하는 방식으로 선언할 수 있다.
반환 자료형 (*이름)(매개변수) = 함수명;
-> 형태가 같은 서로 다른 기능의 함수를 선택적으로 사용 가능하다.
----------
#include <stdio.h>
void myFunction()
{
printf("It's my function.\n");
}
void yourFunction()
{
printf("It's your function.");
}
int main(void)
{
void(*fp)() = myfunction;
fp();
fp = yourFunction;
fp();
return 0;
}
-------------
위 코드를 실행해보면,
두 개의 함수가 차례대로 실행 된 것을 알 수 있다.
==> 함수 포인터를 이용하면 형태가 비슷한 여러 개의 함수를 같은 명령어로 불러올 수 있다.
- 매개변수 및 반환 자료형이 있는 함수 포인터
----------------
#include <stdio.h>
int add(int a, int b)
{
return a+b;
}
int sub(int a, int b)
{
return a-b;
}
int main(void)
{
int(*fp)(int, int) = add;
printf("%d\n", fp(10,3));
fp = sub;
printf("%d\n", fp(10,3));
return 0;
}
-----------------
add, subtract 함수를 만들어보았는데,
위와 같이 매개변수, 반환 자료형이 모두 있는 경우에도
똑같이 함수 포인터를 이용해 함수를 바꿔가면서 실행할 수 있다.
- 함수 포인터를 반환하여 사용하기
#include <stdio.h>
int add(int a, int b)
{
return a+b;
}
int (*process(char* a)) (int, int)
{
printf("%s\n", a);
return add; // 함수 포인터 자체를 반환할 수 있다!
}
int main(void)
{
printf("%d\n", process("10과 20을 더해보겠습니다.")(10,20));
return 0;
}
------------------
..
c언어 프로그램의 모든 함수는 내부적으로 포인터 형태로 관리할 수 있다.
함수 포인터는 자주 사용되지 않지만,
알고 있으면 컴퓨터의 구조를 이해하는 데 도움이 된다고 한다.
올인원 패키지 : 컴퓨터 공학 전공 필수👉https://bit.ly/3i4sCVE
'패스트캠퍼스' 카테고리의 다른 글
| [패스트캠퍼스 수강 후기] 올인원 패키지 : 컴퓨터 공학 전공 필수👉C언어인강 100% 환급 챌린지 25회차 미션 (0) | 2020.11.12 |
|---|---|
| [패스트캠퍼스 수강 후기] 올인원 패키지 : 컴퓨터 공학 전공 필수👉C언어인강 100% 환급 챌린지 24회차 미션 (0) | 2020.11.11 |
| [패스트캠퍼스 수강 후기] 올인원 패키지 : 컴퓨터 공학 전공 필수👉C언어인강 100% 환급 챌린지 22회차 미션 (0) | 2020.11.09 |
| [패스트캠퍼스 수강 후기] 올인원 패키지 : 컴퓨터 공학 전공 필수👉C언어인강 100% 환급 챌린지 21회차 미션 (0) | 2020.11.08 |
| [패스트캠퍼스 수강 후기] 올인원 패키지 : 컴퓨터 공학 전공 필수👉C언어인강 100% 환급 챌린지 20회차 미션 (0) | 2020.11.07 |