패스트캠퍼스 - 컴공전공 - 파일시스템의 이해
파일 시스템 배경,
inode 방식과 가상파일 시스템
파일 시스템
운영체제가 저장매체에 파일을 쓰기 위한 자료구조 또는 알고리즘
1. 비트로 관리하기에는 오버헤드가 너무 크다.
2. 블록 단위로 관리하기로 함 (보통 4KB)
3. 블록마다 고유번호를 부여해서 관리
-> 사용자가 각 블록 고유번호를 관리하기 어렵다.
-> 추상적(논리적) 객체 필요 : file
=> 사용자는 파일단위로 관리 ( 각 파일에서 내부적으로 블록 단위로 관리 )
* 저장매체에 효율적으로 파일 저장하는 방법
가능한 연속적인 공간에 파일 저장
외부 단편화, 파일 사이즈 변경 문제로 불연속 공간에 파일 저장기능 지원 필요
-> 블록체인 : 블록을 링크드 리스트로 연결 (끝에 있는 블록을 찾으려면, 맨 처음 블록부터 주소를 따라가야 함)
-> 인덱스 블록 기법 : 각 블록에 대한 위치 정보를 기록해서, 한 번에 끝 블록을 찾아갈 수 있도록 함
( 각 블록에 대한 주소를 별도로 저장해두고 참조하는 방식)
** 다양한 파일 시스템
•Windows : FAT, FAT32, NTFS -> 블록의 위치를 FAT이라는 자료 구조에 기록
•Linux(UNIX) : ext2, ext3, ext4 -> 일종의 인덱스 블록기법인 inode 방식 사용
- 파일 시스템과 시스템 콜
동일한 시스템콜을 사용, 다양한 파일시스템 지원 가능하도록 구현
•read/write 시스템 콜 호출 시, 각 기기 및 파일시스템에 따라 실질적인 처리를 담당하는 함수 구현
ex) read_spec / write_spec
•파일을 실제 어떻게 저장하는지 다를 수 있음
ex) 리눅스 -> ext4 외 NTFS, FAT32 파일시스템 지원
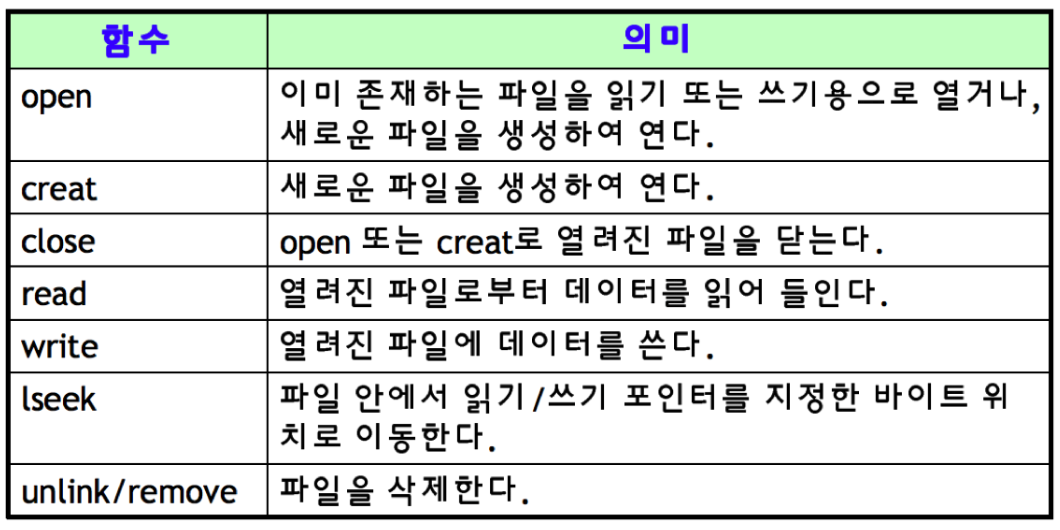
inode 방식과 가상 파일 시스템
- inode 방식의 파일 시스템
* 기본 구조
수퍼 블록 : 파일시스템 정보 (전체적인 정보)
아이노드 블록 : 파일 상세 정보 (PCB)
데이터 블록 : 실제 데이터 (1KB~4KB 등 고정된 사이즈를 갖는다.)
* 수퍼 블록 : 파일 시스템 정보 및 파티션 정보 포함

터미널에서 df 명령어로 확인 가능, (수퍼블록 정보를 읽어서 출력하는 명령어)
수퍼블록은 해당 파일시스템에 대한 대표적인 정보들을 가지고 있는 걸 확인할 수 있다.
* inode와 파일
파일 : inode 고유값과 자료구조에 의해 주요 정보 관리
'파일이름:inode'로 파일이름은 inode 번호와 매칭
파일 시스템에서는 inode를 기반으로 파일 액세스
( 파일 생성 -> inode 번호 -> inode 블록 <- 파일 처리 )
inode 기반 메타 데이터(상세정보) 저장
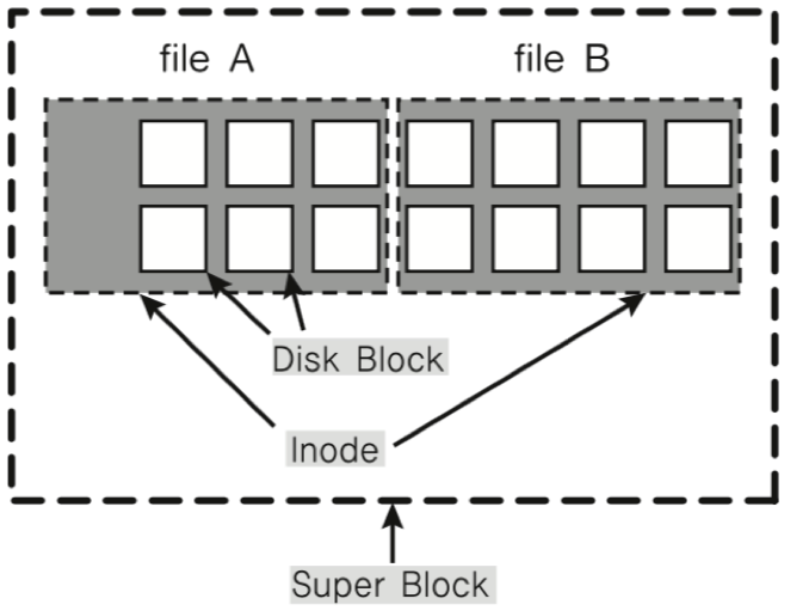
- inode 구조와 파일
inode 기반 메타 데이터(파일권한, 소유자 정보, 파일 사이즈, 생성시간 등 시간 관련 정보, 데이터 저장위치 등)
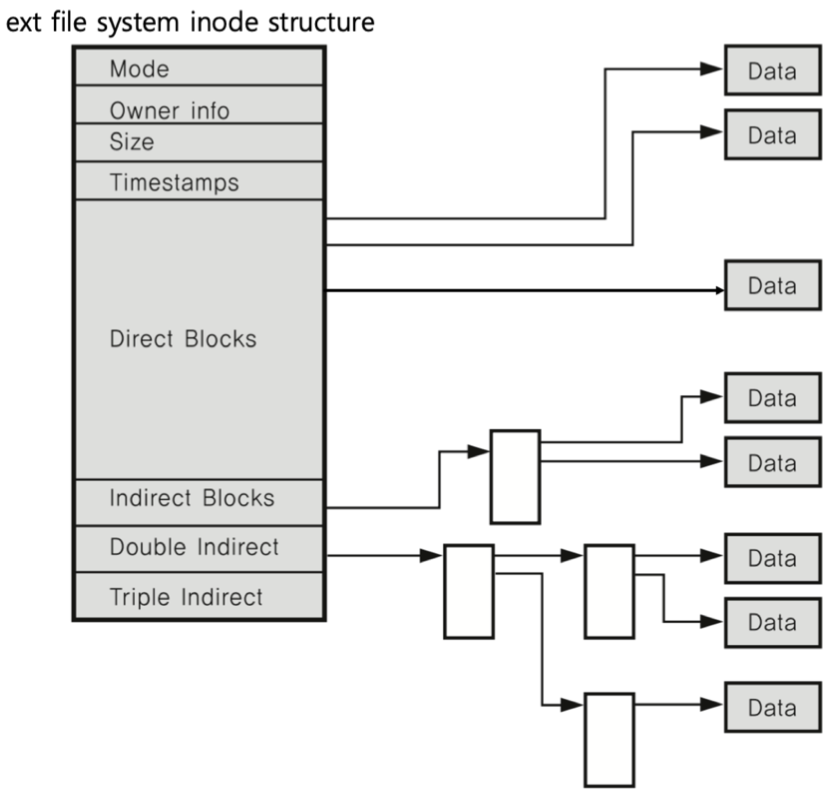
위의 그림은 실제 리눅스의 예시이다.
리눅스는 아이노드 방식을 사용하는 ext file system을 주로 사용하는데,
이 파일시스템의 아이노드 블록을 살펴보면,
메타 데이터는 mode(파일의 권한), owner info(소유자 정보), size, timestamps(시간관련정보)가 있다.
direct block 및 아래부분은 아래에서 다룰 예정

1. cat files.txt
cat : 파일의 내용을 화면에 출력하라는 명령
~ 명령을 하면, 해당 파일의 inode번호를 찾고, inode 번호에 해당하는 블록에 접근한다.
파일에 대한 내용을 출력하라고 했고, Direct Blocks 부분으로 접근하게 된다.
Direct blocks는 파일시스템의 버전마다 다르지만 보통 12개 정도의 주소공간을 갖는다.
각각의 공간이 실제 데이터 블록의 주소를 가리키게 된다.
이후 데이터 블록의 주소에 있는 데이터를 출력하게 되는 것이다.
2. ls -al files.txt
마찬가지로 해당 파일의 inode 번호를 찾고, inode 번호에 해당하는 블록에 접근한다.
파일의 정보를 출력하기 위해
Mode, Owner info, Timestamps 부분에 접근하게 되어 데이터를 출력한다.
- inode 구조와 파일 데이터

가장 상단에 있는 부분은 inode 구조체 블록을 나타낸다.
•single indirect
4KB의 특정 블록을 가리키는데, 이 블록에는 실제 데이터가 있는 것이 아니라
각각의 주소가 4byte로 표현된다고 한다면, 1024개의 실제 데이터를 가지고 있는 데이터블록의 주소를 갖게 된다.
-> 1024 x 4KB = 4MB의 정보를 가질 수 있게 된다.
•double indirect
single indirect pointer의 주소를 가진 4KB의 블록을 가리키는데,
1024의 각각의 블록에
각각 1024개의 데이터블록을 가리키는 주소 를 가리키는 주소를 갖게 된다.
-> 1024 x 1024 x 4KB = 4GB의 데이터를 저장할 수 있는 셈
•triple indirect
위와 같은 방식
-> 1024 x 1024 x 1024 x 4KB 의 데이터 공간을 가질 수 있게 된다.
=> inode 구조에서,
파일사이즈가 작으면 direct block 12개로 해결이 될 것이고,
파일사이즈가 커지면 아래의 indirect까지 활용하게 된다.
** 디렉토리 엔트리
ex) 리눅스 파일 탐색
/home/ubuntu/link.txt
( 맨 처음 '/'은 루트 디렉토리이다. )
1. 각 디렉토리 엔트리 (dentry) 탐색
- 각 엔트리는 해당 디렉토리 파일 / 디렉토리 정보를 가지고 있음
2. '/' dentry 에서 'home'을 찾고, 'home'에서 'ubuntu'를 찾고, 'ubuntu'에서 link.txt 파일이름에 해당하는 inode를 얻음
- 가상 파일 시스템 (Virtual File System)
어떤 파일 시스템이든 일반사용자(프로그래머)는 시스템콜을 사용하면
open, read, write 등을 실행했을 때 동일한 결과를 얻게 한다.
전통적인 유닉스 시스템에서는 그것을 더 확장시킨다.
파일 뿐 아니라 Network 등 다양한 기기도 동일한 파일 시스템 인터페이스를 통해 관리 가능
모든 디바이스를 파일처럼 다룰 수 있게 된다.
ex) read/write 시스템콜 사용, 각 기기별 read_spec / write_spec 코드 구현 (운영체제 내부)
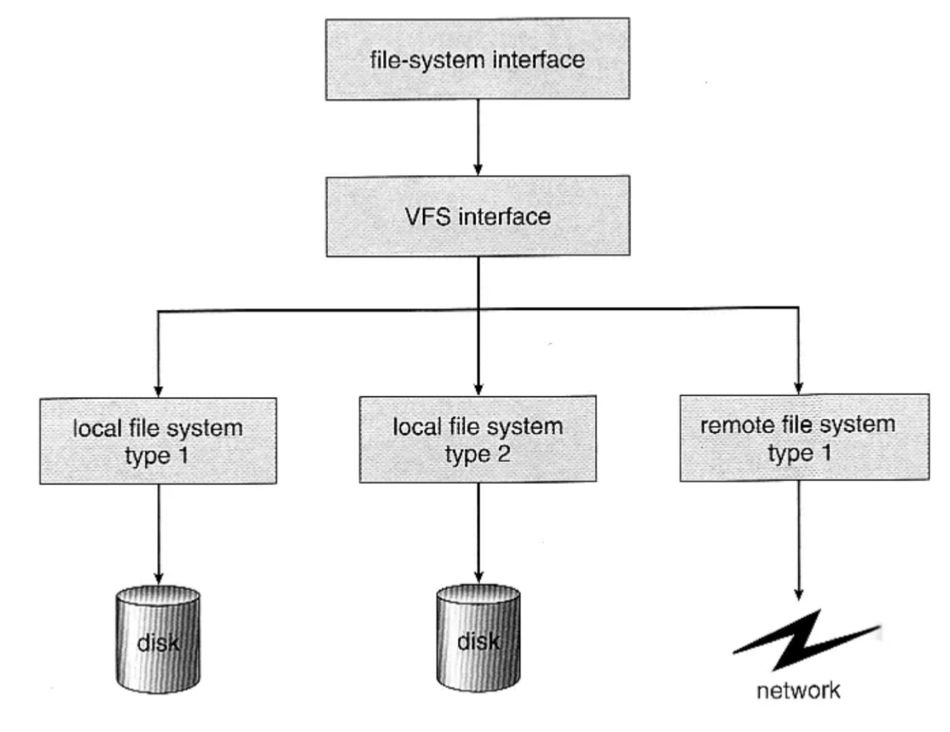
위의 그림은
가상파일 시스템을 통해 네트워크를 파일처럼 다룰 수 있게 된다는 것을 나타낸다.
리눅스(유닉스) 운영체제에서
모든 것은 파일이라는 철학을 따른다고 한다.
모든 인터렉션은 파일을 읽고, 쓰는 것처럼 이루어져 있고
마우스, 키보드 등의 모든 디바이스 관련 기술도 파일처럼 다루어진다.
모든 자원에 대한 추상화 인터페이스로 파일 인터페이스를 활용한다.
(처리해야할 것들을 추상화시켜서 일관되고 단순한 인터페이스로 조작할 수 있게끔 한다.)
** 특수 파일
디바이스
•블록 디바이스 (block device)
HDD, CD/DVD와 같이 블록 또는 섹터 등 정해진 단위로 데이터 전송, IO 송수신 속도가 높음
•캐릭터 디바이스 (character device)
키보드, 마우스 등 byte 단위 데이터 전송, IO 송수신 속도가 낮음
•cd/dev, cat tty
'패스트캠퍼스' 카테고리의 다른 글
| 자료구조/알고리즘 - 프림 알고리즘 (0) | 2020.12.18 |
|---|---|
| 운영체제 - 부팅 (0) | 2020.12.18 |
| 자료구조/알고리즘 - 해시(Hash) (2) | 2020.12.15 |
| 자료구조/알고리즘 - AVL 트리 (0) | 2020.12.15 |
| 운영체제 - 가상 메모리 (0) | 2020.12.10 |